The k th raw moment of a random variable is the expected (average) value of the k th power of the variable, provided that it exists. It is denoted by E(Xk) or by μk′. The first raw moment is called the mean of the random variable and is usually denoted by μ.
Raw moments for continuous variables:
μk′=E(Xk)=∫−∞∞xkf(x)dx
Raw moments for discrete variables:
μk′=E(Xk)=x∑xkp(x)
In particular, μ1′=E(X)=μ
Definition
The k th central moment of a random variable is the expected value of the k th power of the deviation of the variable from its mean. It is denoted by E[(X−μ)k] or by μk. The second central moment is usually called the variance and denoted σ2 or Var(X),and its square root, σ, is called the standard deviation. The ratio of the standard deviation to the mean is called the coefficient of variation.
It is left censored because values below d are not ignored but are set equal to zero. There is no standard name or symbol for the moments of this variable. For dollar events, the distinction between the excess loss variable and the left censored and shifted variable is one of per payment versus per loss. In the per-payment situation, the variable exists only when a payment is made. The per-loss variable takes on the value zero whenever a loss produces no payment. We can calculate the moments by:
The expected value of the above function is called the limited expected value.
Definition
This variable could also be called the right censored variable. It is right censored because values above u are set equal to u. An insurance phenomenon that relates to this variable is the existence of a policy limit that sets a maximum on the benefit to be paid.
Note that (X−d)++(X∧d)=X. That is, buying one insurance policy with a limit of d and another with a deductible of d is equivalent to buying full coverage.
Now we have
E[(X∧u)k]=∫−∞uxkf(x)dx+uk[1−F(u)]
We can derive another interesting formula as follows:
The right tail of a distribution is the portion of the distribution corresponding to large values of the random variable. Understanding large possible loss values is important because these have the greatest effect on total losses. Random variables
that tend to assign higher probabilities to larger values are said to be heavier tailed. Tail weight can be a relative concept (model A has a heavier tail than model B) or an absolute concept (distributions with a certain property are classified as heavy tailed). When choosing models, tail weight can help narrow the choices or can confirm a choice for a model.
We normally have four ways to classify if a random variable is heavy or light-tailed.
If μk′=∫0∞xkf(x)dx<∞ for all k, then the distribution is light-tailed. Otherwise, it is heavy-tailed.
Example:
For the gamma distribution, the raw moments are
μk′=∫0∞xkΓ(α)θαxα−1e−x/θdx=∫0∞(yθ)kΓ(α)θα(yθ)α−1e−yθdy, making the substitution y=x/θ=Γ(α)θkΓ(α+k)<∞ for all k>0.
For the Pareto distribution, they are
μk′=∫0∞xk(x+θ)α+1αθαdx=∫θ∞(y−θ)kyα+1αθαdy, making the substitution y=x+θ=αθα∫θ∞j=0∑k(kj)yj−α−1(−θ)k−jdy, for integer values of k.
The integral exists only if all of the exponents on y in the sum are less than −1, that is, if j−α−1<−1 for all j or, equivalently, if k<α. Therefore, only some moments exist.
By this classification, the Pareto distribution is said to have a heavy tail and the gamma distribution is said to have a light tail.
A commonly used indication that one distribution has a heavier tail than another distribution with the same mean is that the ratio of the two survival functions should diverge to infinity (with the heavier-tailed distribution in the numerator) as the argument becomes large. Note that it is equivalent to examine the ratio of density functions.
Example:
Demonstrate that the Pareto distribution has a heavier tail than the gamma distribution using the limit of the ratio of their density functions.
To avoid confusion, the letters τ and λ will be used for the parameters of the gamma distribution instead of the customary α and θ. Then, the required limit is
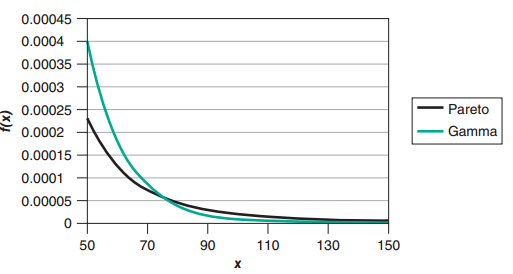
and, either by application of L'Hôpital's rule or by remembering that exponentials go to infinity faster than polynomials, the limit is infinity. Figure below shows a portion of the density functions for a Pareto distribution with parameters α=3 and θ=10 and a gamma distribution with parameters α=31 and θ=15. Both distributions have a mean of 5 and a variance of 75 . The graph is consistent with the algebraic derivation.
Let's review the concept that h(x)=S(x)f(x), if the hazard function is increasing as x increases, then the random variable is light-tailed; if the hazard function is decreasing as x increases, the function is heavy-tailed.
The hazard rate function for the Pareto distribution is
h(x)=S(x)f(x)=θα(x+θ)−ααθα(x+θ)−α−1=x+θα,
which is decreasing when fixing α and θ. Therefore, the Pareto distribution is heavy-tailed.
If the mean excess loss function is increasing in d, the distribution is considered to have a heavy tail. If the mean excess loss function is decreasing in d, the distribution is considered to have a light tail. The pattern is opposite to hazard function method.